



Using Redis Cache? Don't Forget This!
Redis is a great tool for caching, but software engineers often overlook certain aspects, leading to bugs or inefficiencies.

Welcome to Coderbased, a newsletter designed to help you become a bit better at software engineering. We are grounded in real-world experience, not just theory and concepts. Learn one bit at a time.
Before we start, kindly to subscribe, follow me on Linkedin, Twitter and share this content to your friends. Enjoy.
When we talk about improving application or system speed, caching is often one of the first things that comes to mind. And when it comes to caching, Redis is probably the first tool you think of.
Redis caching has been extensively discussed, so I won't rehash the basics. Instead, I want to focus on what software engineers often overlook when using Redis as a cache. These oversights can lead to potential bugs or inefficiencies.
Let’s go to the list.
1. Forgetting to Invalidate or Clear Redis Cache
Imagine you have an API that provides product pricing. Because your site receives high traffic, you cache the product information, including prices.
A common mistake engineers make is forgetting to invalidate or clear the cache when prices change.
For instance, if the price changes from $100 to $120, some users might still see the old $100 price if the cache isn’t properly updated.
Always plan when and how you’ll invalidate the cache to avoid these inconsistencies.
How to clear redis cache? either use TTL or DEL. In this case when the price getting update we need to trigger DEL statement
DEL product:1
2. Not Caching "Not Found" Responses
Let’s say you have an API to fetch product information by ID:
https://api.site.com/product/1
If the latest product ID in the database is 50, then IDs like 51, 52, and so on don't exist. Many engineers skip caching these "not found" responses, but this can be problematic.
When requests bypass the cache, the whole purpose of caching is undermined. In the real world, there might be cases where data existed before but no longer does, yet people still access it, perhaps through Google’s indexing. In a high-traffic environment, this can overload your server.
So, don’t forget to cache the "not found" responses as well. For example, you could cache it like this:
SET product:51 "{}"
3. Using Redis Cache in Non-Atomic Operations
A typical approach when using Redis for caching might look like this:
GET → Process → SET
If the GET statement finds the data in Redis, you return it. But if it doesn’t, the system must perform some processing and then cache the result with a SET statement.
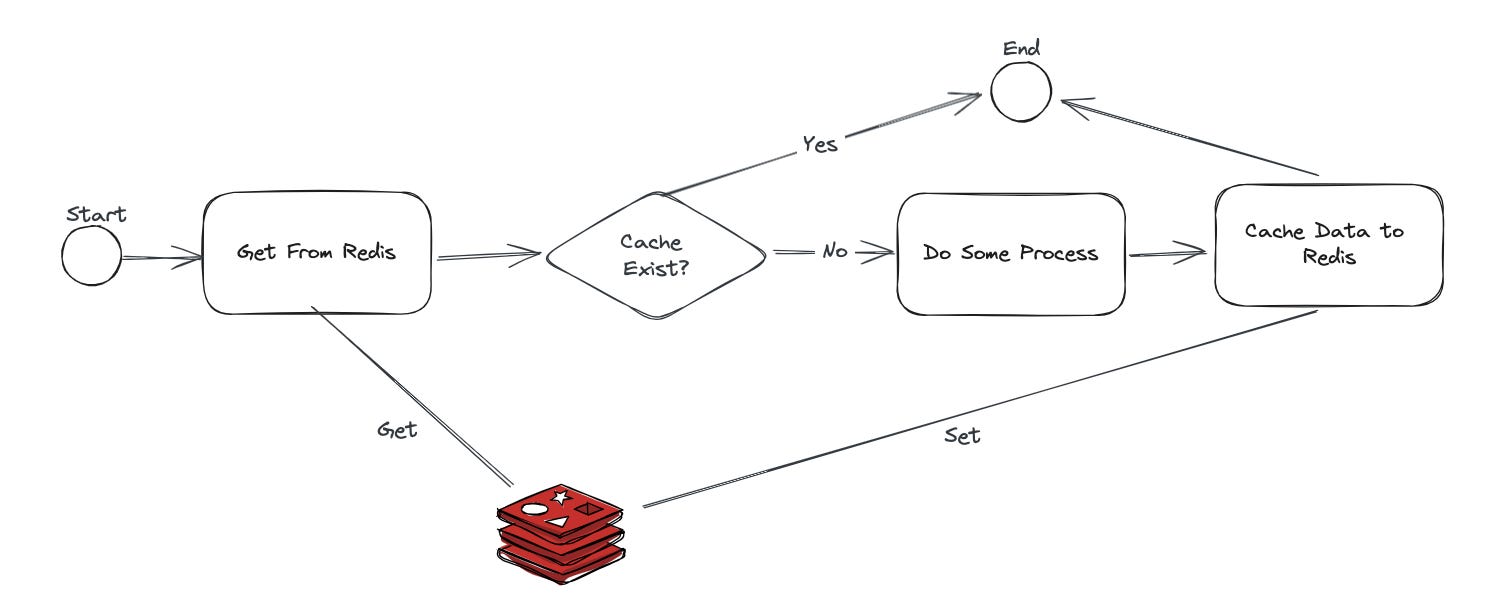
The problem arises in the time between the GET and SET operations. While this approach might work fine in many cases, if the process is complex, resource-intensive, or time-consuming, it can lead to a thundering herd problem.
When the process takes a long time, every request bypasses the cache, putting extra strain on the server.
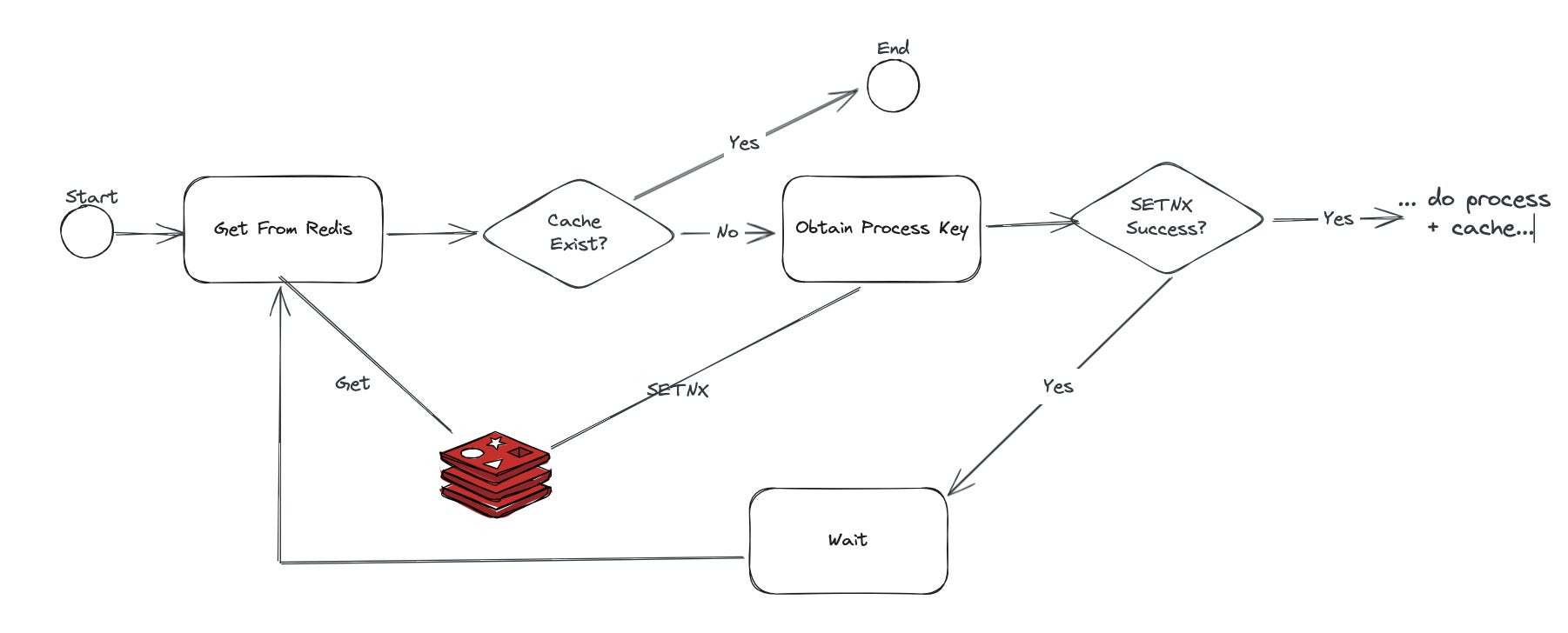
Suggestion: Evaluate the complexity of your logic before applying Redis caching. You can use a single-flight mechanism to ensure that when one process is being handled by the server, other requests wait until the cache is updated. Consider using SETNX for this.
4. Forgetting to Warm Up the Cache
When Redis is restarted or redeployed, the cache is often empty, which can lead to a spike in requests as the cache is rebuilt. If your application can handle this spike, you’re fine. But in many high-traffic environments, this can cause the system to go down.
To avoid this, set up Redis persistence and pre-fill the cache before starting the application. Warming up the cache ensures that it’s not empty when the application goes live.
Did you find other things that software engineers often overlook or forget? Please comment below
mulai aktif lagi nih?